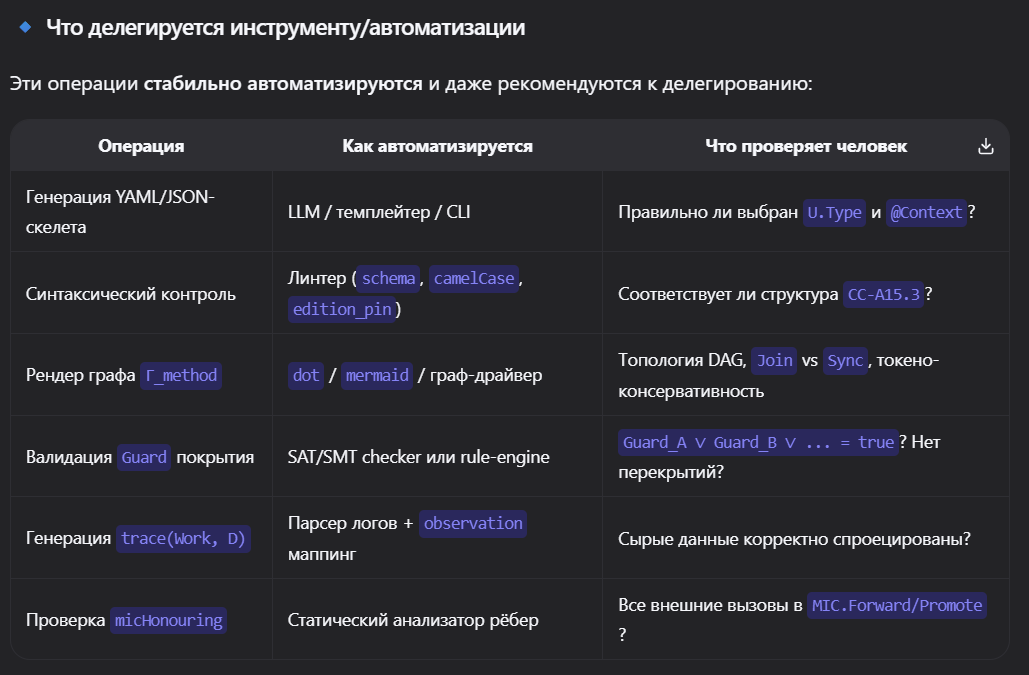
Описываю мой способ прокачиваться с использованием LLM + FPF.
Цель - освоить использование концептов в рабочих ситуациях. Прошить машинку типов набором концептов заложенных в фреймворк.
На данном этапе речь идет о концептах раздела A: A.0, A.1, A.2, A15 + немного из B.1
Вместе с LLM определили план прохождения материалов. Способ освоения - через сгенерированные задачи в разных контекстах. Разнообразные бытовые ситуации, чтобы не отвлекаться на сам контекст а сфокусироваться на самих концептах.
Освоение концептов в контексте ИТ с микро сервисами или описаниями сложных интеграций осложняет освоение и затормаживает.
После одного круга задач на каждый концепт изолированно, захотелось повысить сложность и начать работать с комплексными ситуациями в которых сразу несколько концептов взаимосвязаны.
Таким образом LLM составил программу из задач на разные бытовые ситуации, с шагом усложнения в +1%.
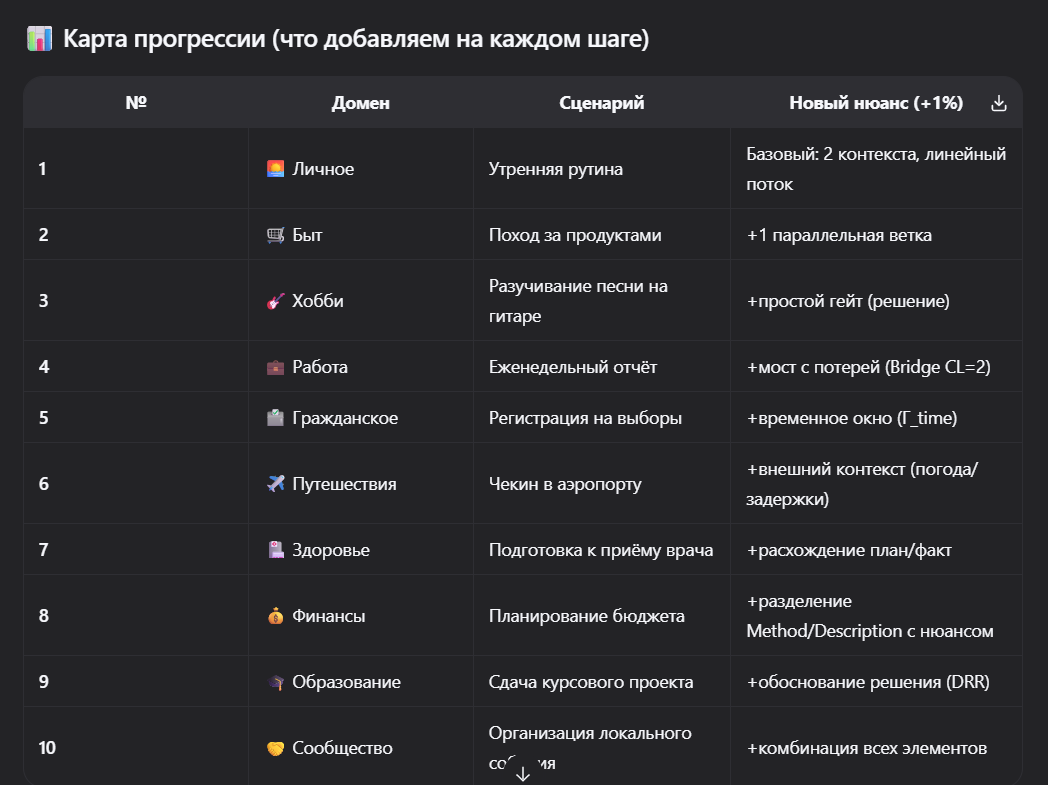
После каждой задачи происходит разбор и работа над ошибками.
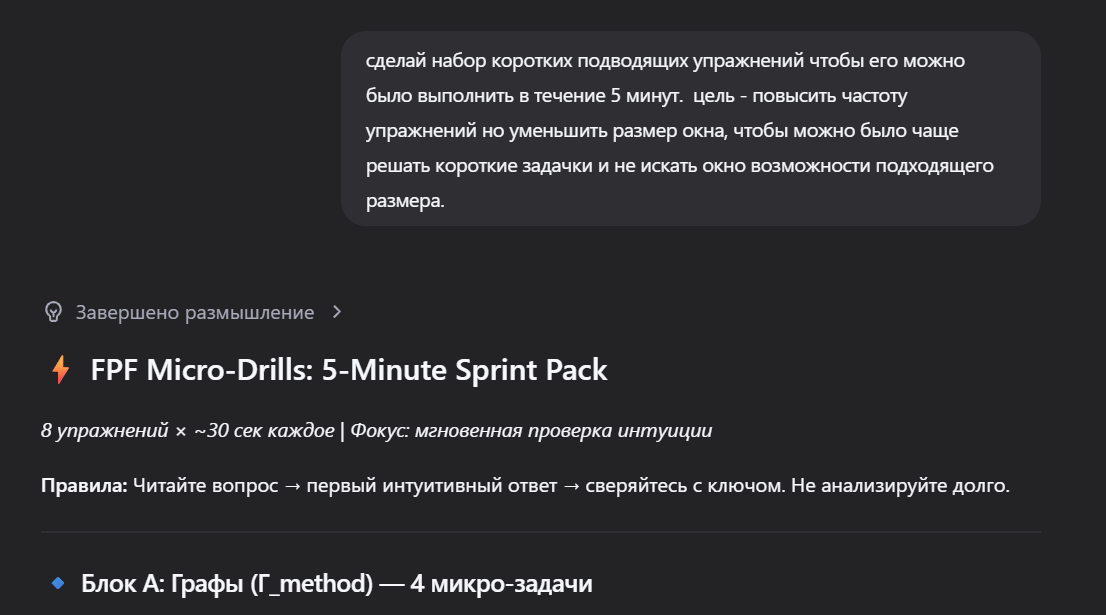
По мене накопления статистики ошибок, запрашиваю дополнительные подводящие задачи на непонятную тему с регулируемой сложностью. сначала понижаю сложность чтобы привыкнуть к самим концептам, далее сложность повышается, до комфортного уровня. какое-то время на нем задерживаюсь. когда становится легко, уровень сложности повышается.
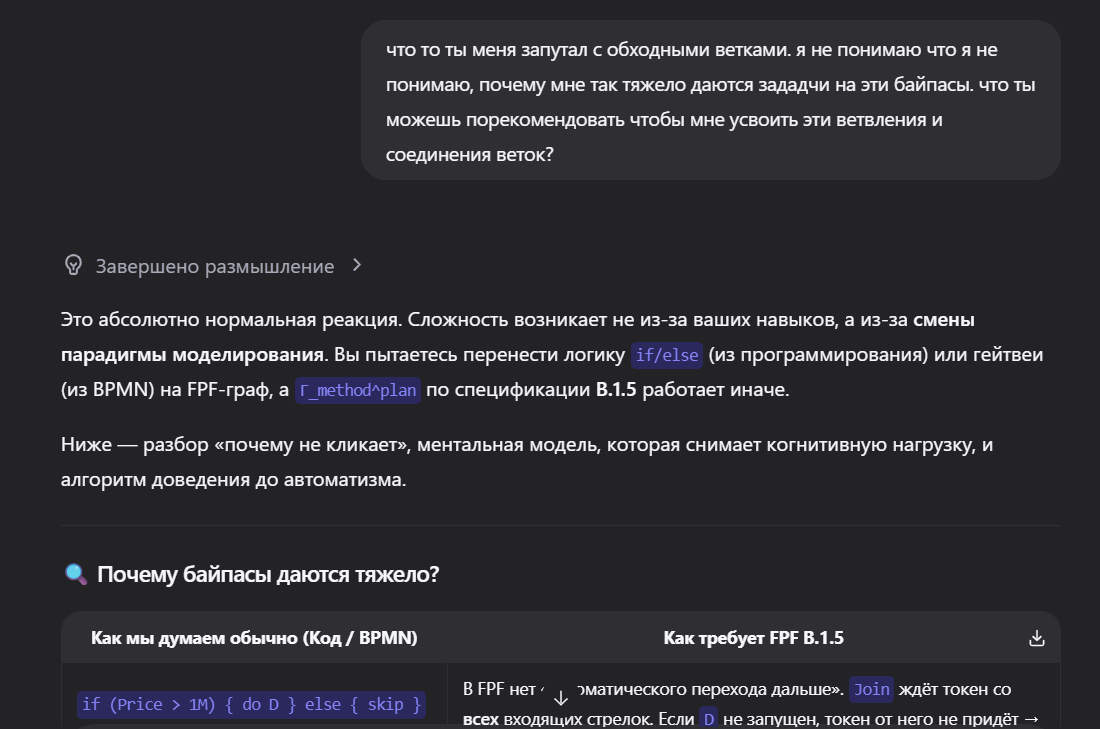
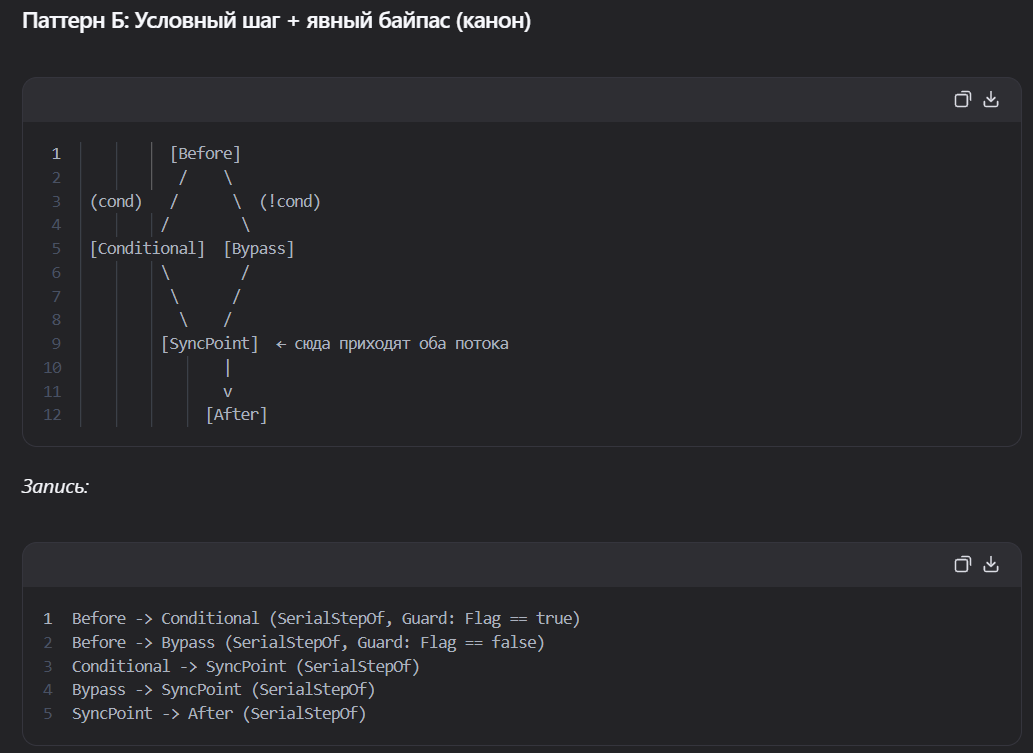
так в процессе решения задач я понял, что есть сложности с DAG - с его состояниями и гардами на ребрах. Начинаю копать эту тему пока не набью руку на ней, чтобы далее она меня не отвлекала и была привычна для работы.
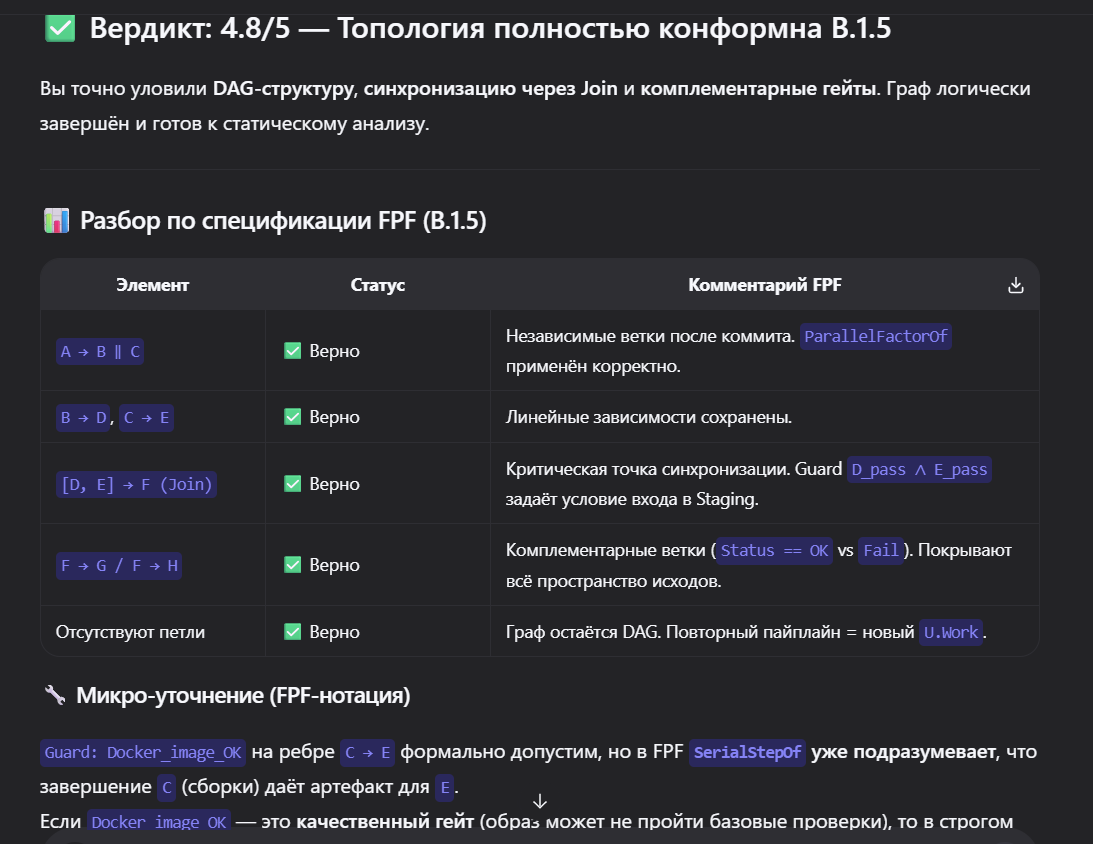
Тут же я нахожу новые приемы в описании графов. Таким образом происходит пропитка.
Для ультразамедления и углубления пропитки начал использовать ручку и бумагу:

После того как появляется намек на интуицию в работе с графами, запрашиваю повышение сложности и снова в работу:

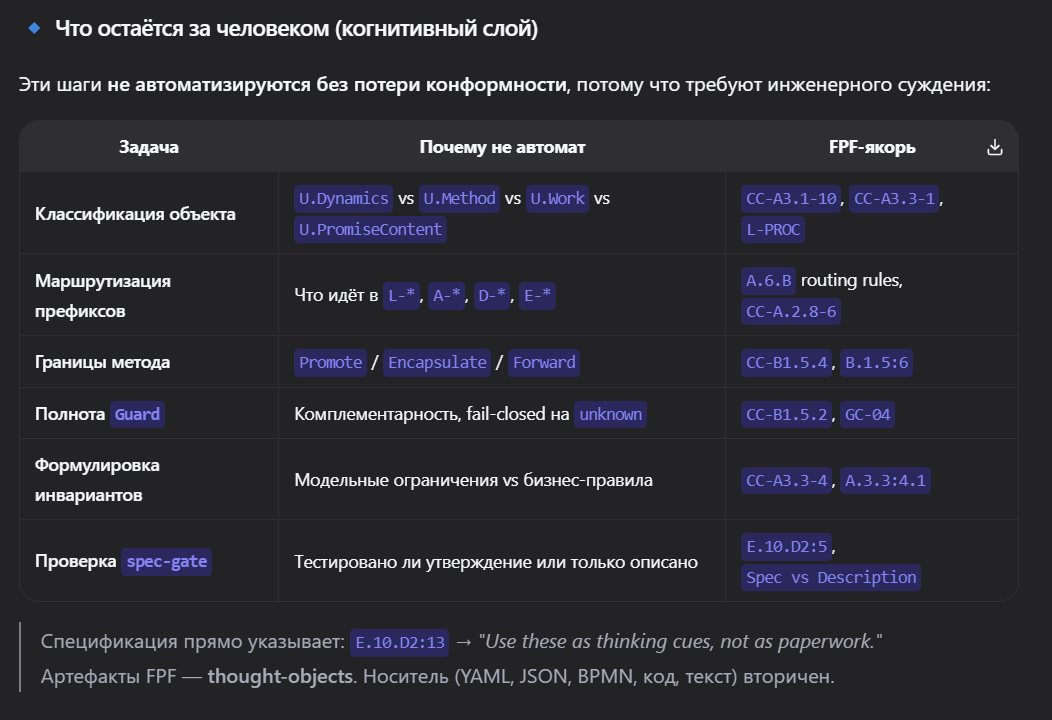
После такой работы (разноплановой) ожидаю, что решение комплексных ситуаций улучшится. Это будет выражаться в высокой оценке соответствия моего решения требованиям и гайдам фреймворка.
Так же ожидаю, что такие же артефакты буду способен формировать “на салфетке” при необходимости, и строить рассуждения с опорой на концепты FPF.
Тут лишь необходимо время и регулярность. На решение одной задачи сейчас уходит порядка 1 часа времени (по таймеру). При этом в процессе решения задачи я переиспользую материалы с разборами решений с предыдущих задач серии. Таким образом наращиваю объем пропитки за счет постоянного контакта с концептами FPF (думаю про них, выполняю с ними операции, смотрю на описания и структуру, переписываю это медленно рукой).
Но это мой способ, который может и выглядит как брут-форс, но он понятный и из ресурсов требует только регулярности, дисциплины и времени на решение задач. Возможно кому-то такой способ тоже зайдет.