в контракте она может быть описана как - поставщик проводит обучение N пользователей, разбитых на группы. объем обучения не более M часов по стоимости часа X рублей.
а у заказчика 10/20/30/40 * N пользователей и они начинают бухтеть и создавать нагрузку и поток проклятий в сторону ИТ. и тут приходится своими силами как минимум формально дообучать оставшихся пользователей, чтобы они чисто формально не смогли заявить что от работы в новой программе они отказываются, тк в отношении них не было проведено обучение.
по технике обычно все более менее понятно. с людьми мало кто понимает как заниматься (одно - сформировать группы обучения и обеспечить явку всех в нужное время в нужном месте - уже задача на которой часть менеджмента ломается).
по моим наблюдениям примерно за год происходит принятие и привыкание к новой сэд на уровне линейных пользователей.
тут слышал от коллеги историю что в одной компании топ-менеджменту не нравится слово “цели” - оно их напрягает, вызывает негативные чувства. предлагали его заменить на что-то более мягкое. хотя в компании практикуется управление по целям.
“слова и важны и не важны”. поработав немного с fpf я чуть успокоился, тк технически можно собирать для своих нужд любой словарь и соединять его мостами. есть риск, что как раз слово “гипотеза” на публике будет вызывать негатив, а “требования” как раз зайдут на ура. имея под рукой онтологию можно собирать необходимый инструментарий на лету. и далее его в процессе донастраивать. или я что-то не верно понимаю?
Для меня вы перечисляете все те вопросы, которые разбираются в руководствах. Что-то фундаментальное (про слова, которые важны и не важны), но что-то весьма прикладное (скажем, чем и как заменять слово “требование” – в руководстве по системной инженерии, например, я давал ссылки на то, как это сделано в SpaceX, про софт и его освоение – в руководстве по системному менеджменту). Тут в комментах нет смысла пересказывать руководства. Насчёт того, что имея под рукой онтологию можно собирать какой-то лексический ход в какие-то тусовки (включая речевое сообщество организации), это да – но с ограничениями, ибо в организациях часто останавливаются на перегруженной терминологией (это когда у термина несколько словарных значений), а потом разные люди в разных контекстах пользуются разными значениями – и вот тут-то и возникают “я не понял, но сейчас понял, беру на переделку” (и плюс месяц проекта на каждый такой случай).
я склоняюсь к гипотезе что это часть стратегии и защитных механизмов менеджмента в корпоративных битвах. они так делают изначально (скорее даже неосознанно) чтобы было пространство для маневра и можно было замаскировать свое непонимание вопроса или отсутвие компетенций.
Нет, это тоже важно. Канцелярит – это как раз лексический способ снять ответственность за текст: как написать много текста, который легко прочесть десятью способами ))) СЭД вроде про канцелярию? Про поручения и приказы? Они будут написаны канцеляритом, но поскольку это просто “документооборот”, то это не будет отслежено. А ведь простейший фильтр с этим работает, но в основе этого фильтра должна лежать онтика. Поставить проход с FPF – там это wording-use ontological precision restoration.
У айтишников это “айтишный матерный”: уход к многозначным словам, где во всяких surface не разберёшь – это файл ли, API ли, или ещё что-то абсолютно разной онтологической природы. Я об этом тоже писал.
И тут надо как у шифропанков: не писать законов, ибо носители мокрых нейросеток не захотят и не смогут их соблюдать, а писать код. Скажем, посадить тот же FPF на проверку текстов. Про правку я пока молчу.
тут мне видится 2 задачи, которые не в периметре проекта: создание и утверждение онтики,
реализация ее в виде модуля и встраивание ее (куда?) в какой-то рабочий контур который (что?) - будет вроде подстановки t9 или автоисправление - заменять канцелярит на что-то …
есть риск что пользователи от такой работы не будут в восторге, так это сломает им голову
меня порой подбешивает когда клавиатура на смарте принимая мое слово (напечатанное как я и хотел) начинает считать ошибкой и самостоятельно его исправляет на правильное (по ее мнению).
Это похоже на попытку починить социальную проблему техническими средствами.
недо отдельно пользователей к такому готовить, чтобы они не думали что система сломалась и выдает им какую-то дичь )))
Работа с упряжью агентов – это как раз рабочие процессы и IT в их основе ))) Корпоративный софт и тамошние нормы в его основы, workflow – это и есть ведь упряжь ))) Я пишу об этом всё время.
Повторюсь: канцелярит люди вставляют намеренно. Сознательно. Убирая свою ответственность. Потом приходите вы (или присылаете своего AI-агента, это всё равно) и убираете канцелярит – это им не понравится. Причины будут называться разные, например, “не соблюдается формальный стиль” (да, конечно!), “ты мне испортил смысл текста” (да, смысл “ни о чём” испортил, подал то, что ты писал “между строк”) и так далее. Дальше возвращаемся: если это вопрос канцелярии, то это проблема, ибо там вопрос “кто виноват” ключевой. Если это issue tracker, то вроде за такое должны говорить спасибо (конечно, это “предлагаемое редактирование”, а не прямая переписка – как с T9).
Вы поработайте с FPF в рабочих проектах. А то вы его, похоже, используете для обучения, а не для работы – а надо для работы ))) Там всё это уже есть в каком-то виде, можно пользоваться.
к сожалению полноценно я его не могу использовать, тк у меня закрытый контур. отсюда и такое специфическое использование LLM.
FPF использую только для генерации артефактов, которые потом руками уже допиливаю на месте. Получаю пачку шаблонов и довожу их на месте до требуемого состояния.
Сценарий использования про который вы говорите мне пока не доступен по даже не по причине технических ограничений.
Заметил, что бывают моменты, когда сложность освоения FPF складывается со сложностью того контекста, который LLM-ка решила подобрать. и не знание предметной области контекста начинает ломать и демотивировать. можно, конечно, заморочиться и разобраться с предметной областью (ну почему бы не посмотреть чем еще в мире люди занимаются и какую могут выполнять работу или решать задачи). Для меня сложность вызывают, как ни странно, контексты из ИТ, особенно те которые про интеграции сервисов, обмены сообщениями. Это отдельный вид искусства.
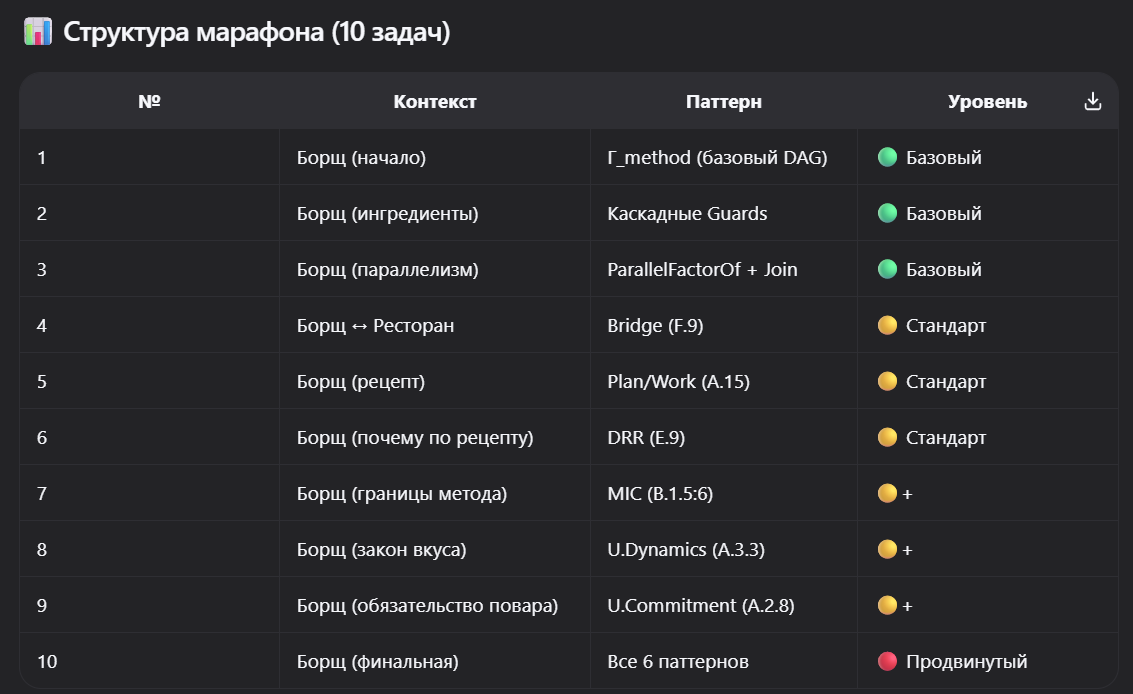
получилось дотащить 1-ю десятку задач с набором вбоквилов.
на этот раз, чтобы увеличить пропуск по задачам и снизить гранулярность, снизил сложность и решил добавлять в задачи концепты постепенно, по мере продвижения по списку задач.
чтобы не тормозитсья об контексты заказал контексты на базе сказок.
Мои ожидания в том, что это высвободит часть ресурсов внимания на разбирательство с самим доменом (который может быть не знаком или сложен сам по себе). Далее буду наблюдать.
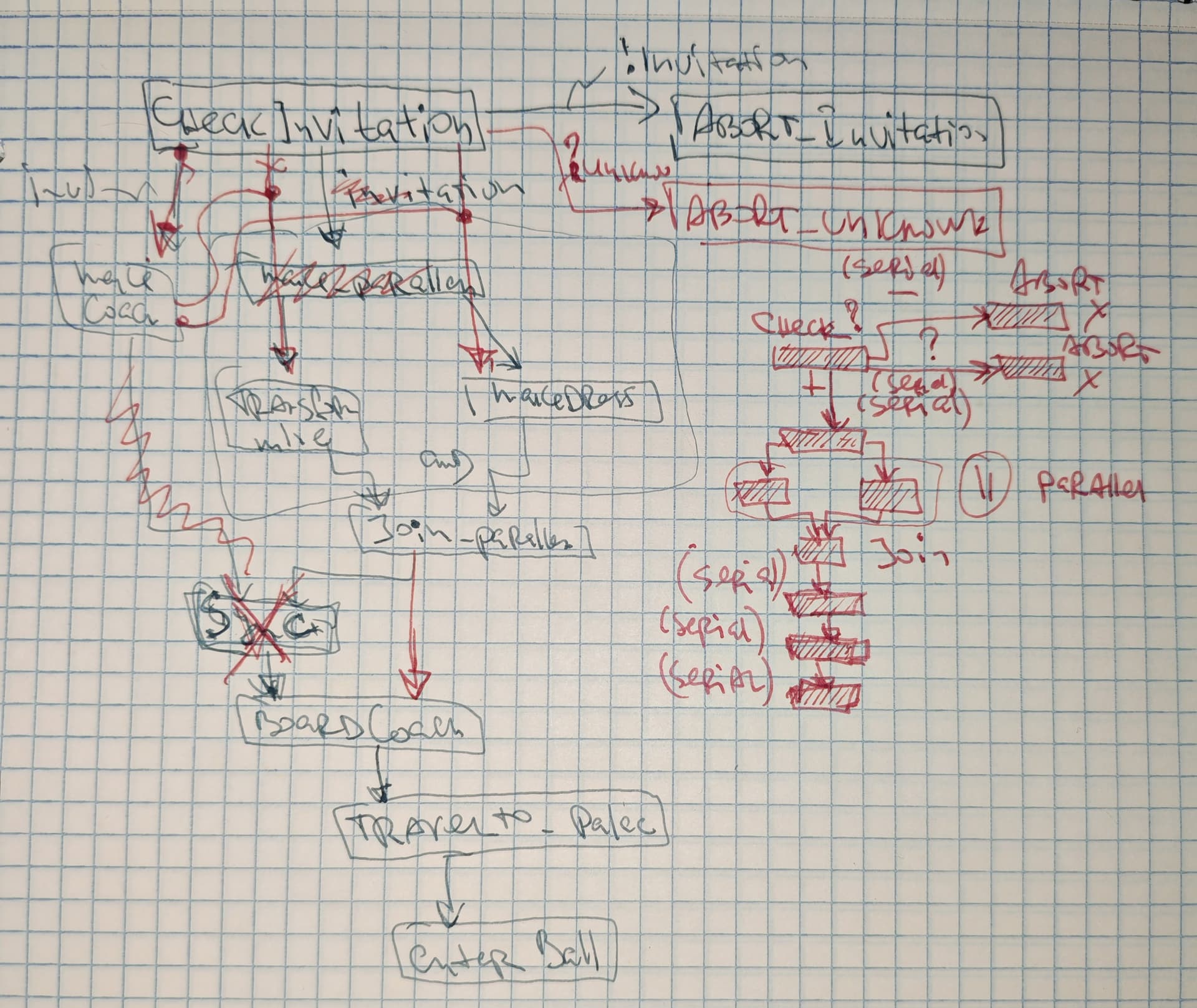
Тема с DAG выглядит достаточно полезной в рабочих задачах, когда надо разбираться с логикой бизнес-процессов которые рождают представители бизнеса. соответственно, акцент пока на этой теме. Даже на заранее подготовленных вершинах из задачи без ошибок пока не получается с 1го раза построить небольшой DAG. Но после первой 10-ки задач эта тема уже не выглядит страшно. есть понимание про то как эти графы строятся, какие там есть основные приемы. надо только нарешать задач и привыкнуть к особенностям DAG.
DAG это самое простое из того что не понятно и с чем не привычно работать. Далее MIC, SlotFillingsPlanItem vs U.Work, DRR, U.Dynamics. вот где жесть начинается. Там своя атмосфера )))
Параллельно можно пропитаться формальным инженерным языком, и поправить собственную лексику при общении с коллегами.
Вот кто против такого откроет спор, прочитав это в корпоративной переписке:
Ну значит, завершил свой собственный марафон по fpf применительно к сказочным контекстам.
по личным ощущениям, начинает формироваться интуиция про то как артефакты внутри себя устроены, как они друг на друга ссылаются в рамках рассматриваемых ситуаций и уже не так непонятно что и куда надо записывать. но главное тут - не что, а почему.
еще парочка таких марафонов и будет еще проще.
по итогам марафона llm выдает краткую справку о прогрессе. там он отмечает что есть у меня сложности с синтаксисом yaml. на что я возразил, что очевидно что такие тексты руками в таком объеме я в будущем писать не планирую, и эта часть будет делегироваться LLM ке которая заведомо быстрее и точнее этот синтаксис обеспечит. после чего мои оценки были скорректированы.
Собственно, использовать такой подход для освоения fpf - вопрос на который каждый должен сам себе ответить ) . в качестве замедления чтобы вдумчиво проникнуться в суть - оно норм. только печатать надо много. но оно дает хорошую пропитку.
Запросил варианты контекстов на следующий марафон, с таким же уровнем сложности, без глубоких ит-тем про интеграции. передоложенный вариант выглядит заманчиво: