Поскольку в IWE быстрые служебные вызовы исторически завязаны на семейство Anthropic, сторонние модели приходится подставлять через алиасы. В Pi это делается легко.
Задача была простая: заменить Haiku в быстром служебном слоте Pi. Такие вызовы требуют изоляции: не нужно беспокоиться о передаче лишнего контекста, дополнительных вызовах инструментов и побочных эффектах.
В Pi есть нативная поддержка нескольких моделей и возможность вызывать их прямо из чата. Поэтому появилась идея не выбирать замену на ощущениях, а прогнать тесты и понять, какие модели реально подходят по скорости и надёжности.
Важно: речь не про «самую умную модель вообще».
У агента есть слой коротких служебных задач. Там модель не ведёт длинный разговор и не решает большую архитектурную проблему. Она делает маленькую операцию внутри конвейера: классифицирует сообщение, вытаскивает дату и действие, проверяет чеклист, находит простой запах кода, возвращает строгий JSON.
Для такой роли нужна не максимальная интеллектуальность, а предсказуемость.
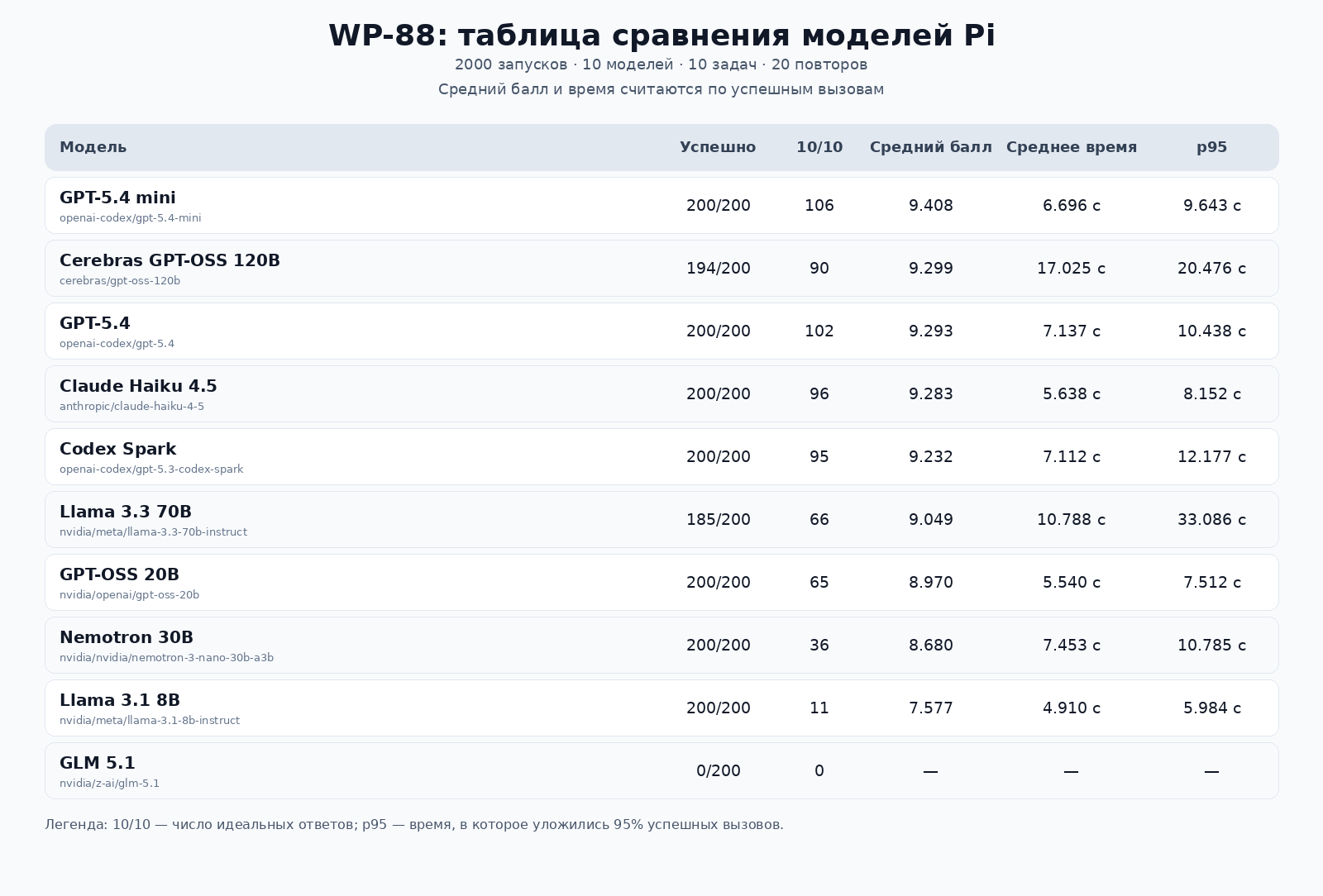
Мы сначала сделали узкий прогон по доступным моделям, а потом расширили проверку, чтобы не попасть в ошибку малой выборки. Итоговый прогон: 10 моделей, 10 задач, 20 повторов на каждую пару. Всего 2000 запусков.
В тесте участвовали:
-
Haiku - чтобы понимать базовые характеристики исходного слота;
-
Codex-модели - отдельно интересен Spark, потому что у него отдельные лимиты в тарифе Pro;
-
бесплатные модели от Nvidia и Cerebras.
Что проверяли:
-
понимает ли модель намерение пользователя;
-
правильно ли извлекает дату и действие из напоминания;
-
держит ли чеклист;
-
различает ли простой запах кода;
-
возвращает ли ответ в нужном формате;
-
насколько стабильно повторяет результат.
Главная находка: самая быстрая модель не обязательно лучшая для служебного слоя.
Если модель отвечает за 2 секунды, но иногда ломает формат или путает действие, она создаёт скрытую цену. В обычном чате это может быть просто неточностью. В агентном конвейере следующий шаг уже получает неправильные данные.
В расширенном тесте лучший средний баланс по качеству показал GPT-5.4 mini: 200 успешных запусков из 200, 106 идеальных ответов, средний балл 9.408 из 10.
Claude Haiku 4.5 как исходный ориентир тоже оказался сильным: 200 успешных запусков из 200, 96 идеальных ответов, средний балл 9.283.
Codex Spark показал близкий результат: 200 успешных запусков из 200, 95 идеальных ответов, средний балл 9.232. Его мы выбрали как текущий быстрый слот для Pi.
Отдельный урок: результат зависит от набора задач. В первом узком тесте лучше выглядел Nemotron 30B. После расширения выборки картина изменилась. Поэтому один удачный прогон нельзя превращать в вечный рейтинг моделей.
Вывод для агентных систем такой: модель нужно выбирать не вообще, а под рабочее место.
Модель для разговора, модель для кода и модель для короткого служебного JSON-вызова - это разные роли. У каждой роли должен быть свой тест.
Для быстрого служебного слота важны четыре свойства:
-
держит формат;
-
не путает простые намерения;
-
стабильно работает на повторах;
-
быстро возвращает результат без редких длинных задержек.
Побочный вывод тоже важный. Если в Pi уже есть удобный доступ к разным моделям через авторизацию и вызов из чата, то мультиагентность становится проще технически. Но тогда быстрее возникает другой вопрос: нужен оркестратор задач и гардрейл безопасности, чтобы разные модели не просто вызывались, а работали в управляемом контуре.
Итог: быстрый слот - это не место для самой эффектной модели. Это место для модели, которая скучно, стабильно и предсказуемо делает свою маленькую работу.